Kako sačuvati off-line ceo sajt
Moj kompjuter na koji hoću da sačuvam sajt : WIN10/64
Sajt je interni u unutrašnjoj mreži, ali sa njim ima dva problema :
1. Redirektuje, jer traži user+pass za logovanje
2. Ima sertifikat koji nije root
Evo koje sam free alate probala :
1) Cyotek Web Copy
Na prvi pogled deluje super, ali javlja silne greške, i ne uspevam da mu “poturim” user i pass za sajt.
Postavila sam pitanje na njihovo forumu, pa ćemo videti.
Kako se isključuje provera sertifikata :
If the SSL certificate associated with a website is invalid or untrusted, WebCopy will refuse to copy the site. You can force such sites to be copied by ignoring certificate errors.
From the Project Properties dialogue, expand the Advanced category and select Security
Check the “Ignore certificate errors” option
Napomena : zbunjuje me pošto i dalje javlja da je nesiguran sertifikat kada probam da uradim “Capture form”?
Using a web browser to log in
Select Forms and Passwords from the Project menu and select the Passwords category
Check the Log in using a web browser option
Napomena : radi kada sajt nije zaštićen sa user+pass kombinacijom. Uzdah.
2) HTTrack
Malo mator (iz 2017)
Pamti projekat kao *.whtt
Koristi to da sebe treba privremeno staviti kao proxy u IE, ali kao svoju IP adresu daje SAMO IPv6!!!!!
Pošto je u pitanju interna mreža IPv6 nije uopšte omogućen. Jedino rešenje koje sam našla je da se uradi ovo : [IPv6]
, tj da se IPv6 adresa stavi u uglaste zagrade.
Ovde je dobro objašnjenje kako bi to trebalo da radi (ali ne radi).
Napomena : WinHttrack does not have a stop and resume. It only has a Pause/resume and a Cancel/continue. If you Pause you then Resume right where it left off. You can not close httrack.
Dobar link sa nekim osnovnim uputstvom za rad.
Don’t shutdown. Pause httrack and hibernate.
Rešenje :
a) Koristiti Google Chrome
b) Ići na More tools/Developer Tools

c) U Chrome-u otvoriti željeni sajt i ulogovati se
d) U Developer Tools delu Chrome prozora, ići na stavku “Cookies”, “Ime vašeg sajta”
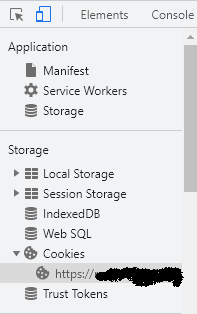
e) Kopirati vrednost pod stavkom “_vaš sajt_session_” (to je jedna OGROMNA kobasica alfanumerika)

f) U HTTRack, kada se dodaje URL, prvo dodati URL sajta koji želite da sačuvate, onda URL za login stranu i onda na kraju dodati “kobasicu” iz predhodne tačke
Dobar link
OBAVEZNO uz URL sajta i login strane dodati i user i pass, u obliku : http://user:pass@www.someweb.com/private/mybox.html
Ovo uraditi za sve delove sajta koje HTTRack inače neće da skine!!!!!
Nema veze što su u pitanju delovi ISTOG sajta, imaju različite kolačiće!
g) Na kraju treba da se dobije :
Kako je gore opisano, HTTRack spušta sajt, i spusti oko 70%, i ne spusti sve. Pošto se sajt MNOGO grana, pokušala sam da stavim neka ograničenja :
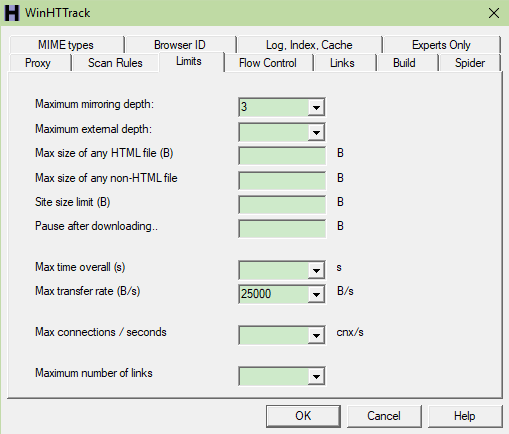
Ako se ova podešavanja koriste količina podataka je MNOGO manja (bez je 8,45G sa je 333MB), ali se čini da su isti fajlovi pokupljeni.
Greške koje se mogu javiti u logu HTTrack-a :
a) Warning: File seems complete (same size), but there was a cache read error
b) Error: “Not Found” (404) at link https://…..
Pokušaj rešenja sa (tj slika dole) :
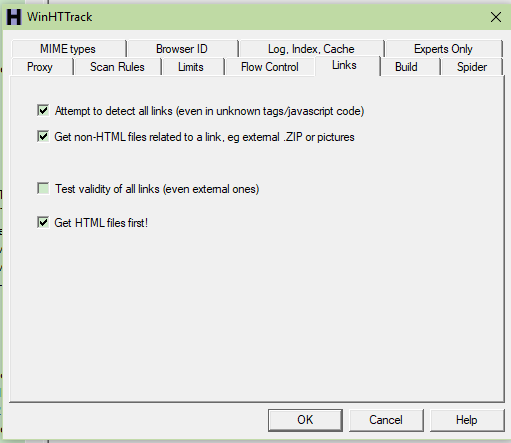
options -> Links -> Attempt to detect all links
options -> Links -> Get non-HTML
Na žalost ovo ne uklanja sve ovakve greške…..
Ali pošto je uzrok : Not found = bad links on the site i ne može 🙂
c) Warning: HTML file (9876 bytes) retransferred due to lack of cache
Ovo se izgubi ako se “otčekuje” opcija “Get HTML files first”
d) Error: Unexpected robots.txt error – ovo se izbegne tako što se isključi poštovanje robot.txt fajla (taj fajl se nalazi na sajtu i služi za određivanje načina pretrage sajta, i HTTrack ga po default-u poštuje) :

e) Error : “Error when decompressing”
f) Error : Unable to get server’s address
Ubaciti podatke o proxy serveru i njegovom portu, iako je (bar u mom slučaju) sajt potpuno lokalan (u unutrašnjoj mreži), čime se broj ovih grešaka dosta smanjuje.
g) Error “Forbidden” (403)
Ovo se može ukloniti ako se izmeni browser u “Set options”/Browser ID” (link) :
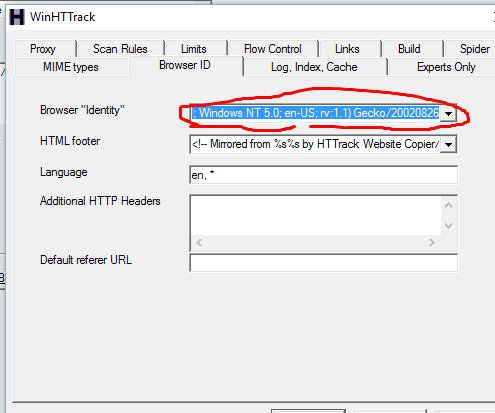
Ako se browser stavi na “None” “403” grešaka maltene više nema!!!!!
Druga mogućnost : changing “Browser ‘Identity'” from the default of “Mozilla/4.5 (compatible: HTTrack 3.0x; Windows 98)” to “Java1.1.4”. I chose the Java identity because it didn’t contain the substring “HTTrack”, which may have been the reason I was being blocked.
h) Error “Service unavailable (503)”
You are probably crashing the site.
Set it to one connection, one connections/sec, 5kb/s (smanjuje zagušenje pri download-u)
i) Warning: Unexpected 412/416 error (Requested Range Not Satisfiable)
Ovo je prouzrokovano izmenom/pomeranjem sajta.
Problem
Problem je to da i pored raznih podešavanja ostaje isti : HTTrack NE skida ceo sajt (proveravala sam i bez obzira na postavku isti delovi sajta su spušteni odnosno nisu spušteni).
3) Getleft
Vrlo malo opcija, javlja grešku “Unsupported protocol”
Odustajem od njega.
4) BimeSoft Surf Offline
Trebalo bi da radi sa sajtovima koji imaju user+pass.
Plaća se, pa sam odustala.
5) wget
Download wget for WIN10/64
Koristi se iz komandne linije (otvoriti cmd “As Administrator”).
Spušta se fajl sa imenom wgetforwin10.exe, i pod tim imenom se i poziva (bez ekstenzije, naravno).
Dobijanje help-a : wgetforwin10 -h
Ovo će izlistati sve opcije.
Ako se spušta spoljašnji sajt, prosleđuju se i podaci o proxy serveru (ako on postoji) :
wget -e http_proxy=http://proxy:port –recursive ime.sajta
Ovo je odlično skinulo sajt van lokalne mreže :
wgetforwin10.exe –recursive –mirror -e http_proxy=http://10.10.10.10:80 linuxkitchen.com
Za sajt u unutrašnjoj mreži, koji ima ne-root sertifikat i traži username+pass :
wgetforwin10.exe –no-parent –save-cookies=”folder.za.download/kolacici.txt” –keep-session-cookies –auth-no-challenge –user=velda –ask-password –convert-links -e robots=off –level=2 –output-file=”folder.za.download/wget.txt” -e http_proxy=http://10.10.10.10:80 –trust-server-names -p -U mozilla –no-check-certificate –recursive –mirror https://sajt.koji.skidam/projects/blabla/wiki
Ne prosleđujem direktno lozinku zbog bezbednosti, a i zato što je komanda ne prihvata zbog verzije HTTP-a.
Kolačići : zato što mi inače ne pravi index.html stranu nego login stranu, iako sam dala user+pass
Namerno sam usmerila stdout na log fajl, da mogu posle sve na miru da pogledam, a log fajl pratim iz PowerShell-a sa komadom :
Get-Content logfajl.log –Wait
Recursive Download – This means that Wget first downloads the requested document, then the documents linked from that document, then the documents linked by them, and so on. In other words, Wget first downloads the documents at depth 1, then those at depth 2, and so on until the specified maximum depth.
Šta znače svičevi :
–no-parent means don’t search parent directories
–random-wait to make sure you don’t get blacklisted from a site
-r recursively downloads
-e robots=off ignores robot.txt files
-U Mozilla makes the user look like its Mozilla I think
-E ili –adjust-extension
If a file of type application/xhtml+xml or text/html is downloaded
and the URL does not end with the regexp \.[Hh][Tt][Mm][Ll]?, this option
will cause the suffix .html to be appended to the local filename.
-k ili –convert-links
After the download is complete, convert the links in the document to
make them suitable for local viewing. This affects not only the visible
hyperlinks, but any part of the document that links to external content,
such as embedded images, links to style sheets, hyperlinks to non-
HTML content, etc.
*****
Dve zanimljive definicije :
Mirroring refers to downloading the entire contents of a website, or some prominent section(s) of it (including HTML, images, scripts, CSS stylesheets, etc). This is often done to preserve and expand access to a valuable (and often limited) internet resource, or to add additional fail-over redundancy.
Scraping refers to copying and extracting some interesting data from a website. Unlike mirroring, scraping targets a particular dataset rather than the entire contents of the site.